The development of modern intelligent city highly relies on the advancement of human-centric analysis technologies. Intelligent multimedia understanding is one of the essential technologies for visual analysis which requires many human-centered and event-driven visual understanding tasks such as human pose estimation, pedestrian tracking and action recognition.
In this grand challenge, we focus on very challenging and realistic tasks of human-centric analysis
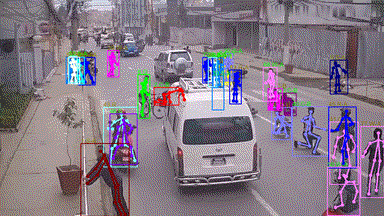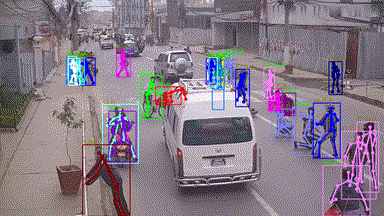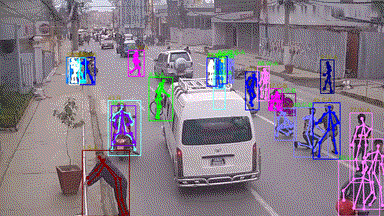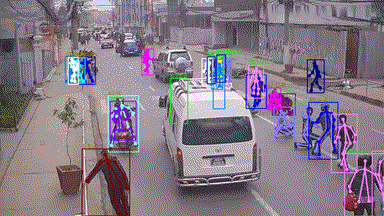
in various crowd & complex events, including subway getting on/off, collision, fighting, and earthquake
escape (cf. Figure. 1). To the best of our knowledge, few existing human analysis approaches report
their performance under such complex events. With this consideration, we further propose a dataset (named as Human-in-Events or HiEve) with
large-scale and densely-annotated labels covering a wide range of tasks in human-centric analysis.
Our HiEve dataset includes the currently largest number of poses (>1M), the largest number of complex-event
action labels (>56k), and one of the largest number of trajectories with long terms (with average trajectory length >480).
More information and details about our dataset can be found here.
Four challenging tasks are established on our dataset, which aims to bring together researchers in the multimedia and computer vision communities to enhance the performance of human motion, pose, and action analyzing methods in 3 aspects:
• Organize challenges on our large-scale dataset with a comprehensive tasks of human-centric analysis and facilitate the multimedia & AI researches & applications in human-centric understanding.
• Encourage and accelerate the develop of new techniques in the areas of human-centric analysis and understanding in complex events.
• Foster new ideas and directions on “Large-scale human-centric visual analysis in complex events”.
 |
 |
 |
 |
| (a) | (b) | (c) | (d) |





